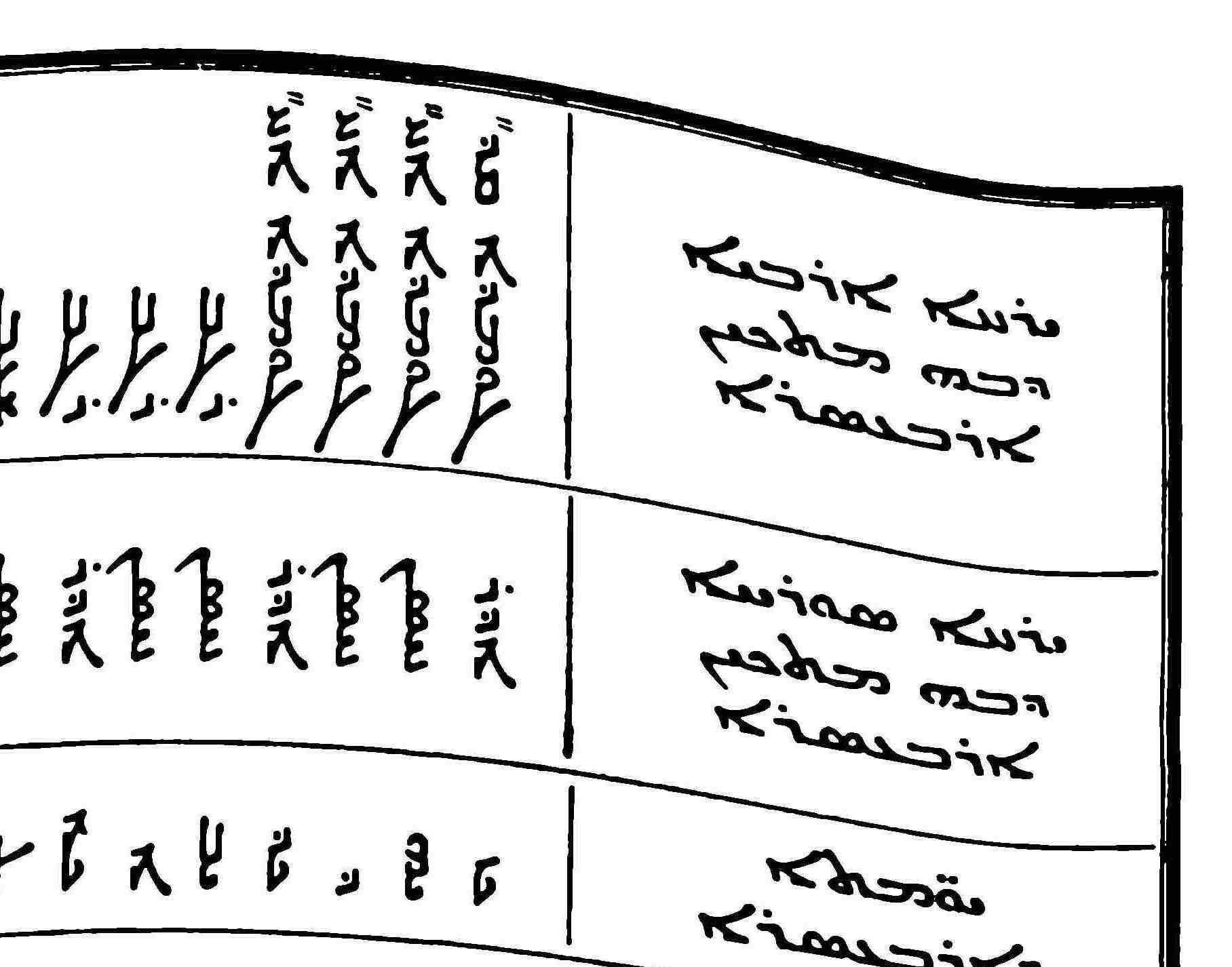
Calfa OCR
Dedicated to oriental languages and manuscripts
Use AI-based models to run text recognition and extract data from your scanned documents, archives, books, and push them to their full digital potential.